Welcome, Kapamilya! We use cookies to improve your browsing experience. Continuing to use this site means you agree to our use of cookies. Tell me more!
UP mathematicians develop AI-powered Baybayin translator
UP mathematicians develop AI-powered Baybayin translator
ABS-CBN News
Published Jul 11, 2023 01:10 PM PHT
|
Updated Jul 11, 2023 02:36 PM PHT
Handout photo.
MANILA –– Mathematicians from the University of the Philippines (UP) Diliman have invented a computerized method to convert text written in the ancient Filipino Baybayin writing system into understandable text.
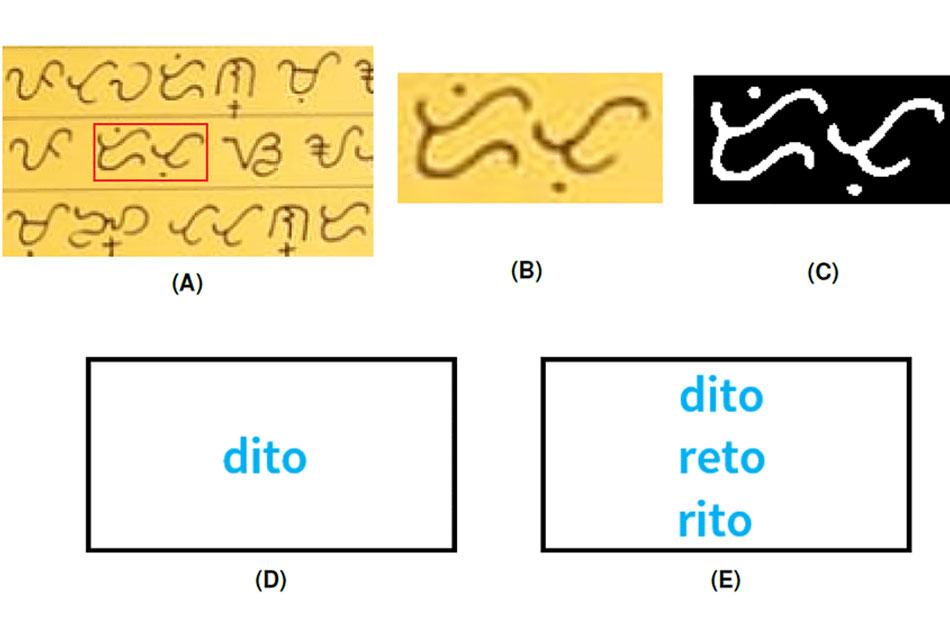
The UP College of Science Institute of Mathematics said it has made what is likely the world’s first paragraph-level optical character recognition (OCR) system that can distinguish between entire blocks of Baybayin and Latin characters in a text image.
In their paper titled “Block-level Optical Character Recognition System for Automatic Transliterations of Baybayin Texts Using Support Vector Machine,” masters student Rodney Pino and associate professors Dr. Renier Mendoza and Dr. Rachelle Sambayan developed an algorithm to convert a photograph of a set of text into binary data, which is then run through a support vector machine (SVM) character classifier to automatically determine whether the characters are Baybayin or Latin.
“SVM is a machine learning algorithm used to solve regression or classification problems. We have a dataset for Baybayin characters — let’s say character A and then character BA. SVM uses techniques or mathematical methods that can separate the two datasets to determine characters BA and A,” Pino said in a release.
ADVERTISEMENT
The group collected over 1,000 images for each Baybayin character, gathering a total of 110 paragraphs from different websites that have either hand- or type-written Baybayin, Latin, or Baybayin and Latin writing, “Adding more character images improves the recognition rate of SVM,” Pino explained.
The current OCR system can spell out the Latin equivalent of the Baybayin characters on a page, thus producing a transliterated version of the text but the researchers are looking to enable it to do so much more, they said.
They also plan to make the OCR system more aware of the context of Baybayin words and phrases to be a full-fledged translator and make the system work both ways, with the ability to convert Latin words with foreign sounds into Baybayin.
“We’re trying to refine the software we developed to make it easier for future users to navigate it. We also dream of creating a mobile application that automatically and accurately translates Baybayin characters just by hovering over the phone,” Mendoza said.
Mendoza said that it was challenging to get the OCR system to translate Baybayin words and sentences accurately.
“For now the system can’t distinguish between some Baybayin characters that are similar in writing, such as E and I, and O and U. We also have a lot of words that have different Latin equivalents. The algorithm we used shows all possible translations of the Baybayin words,” he said.
The team published their data to encourage more researchers to conduct studies on Baybayin and OCR.
“We cleaned the data in such a way that researchers could use it in analyzing Baybayin through other algorithms. We made the data readily available for use, so researchers wouldn’t go through the difficulty we experienced in gathering data,” Mendoza said.
The scientists said that Baybayin is living proof that Filipinos have our own technically-sophisticated traditions, noting that conducting more research on the said text will help preserve this heritage.
“This can be forgotten. It’s important to have a record of each Baybayin character — even having digitized ones,” Sambayan said.
“We’re hoping that through this OCR system, we could preserve and pass on the knowledge of understanding Baybayin to future Filipino generations,” she added.
ABS-CBN is the leading media and entertainment company in the Philippines, offering quality content across TV, radio, digital, and film. Committed to public service and promoting Filipino values, ABS-CBN continues to inspire and connect audiences worldwide.
Our website is made possible by displaying online
advertisements to our visitors. Please consider supporting
us by disabling your ad blocker on our website.
Our website is made possible by displaying online
advertisements to our visitors. Please consider supporting
us by disabling your ad blocker on our website.